1 Experiment Setup
To ensure reproducibility and validation of the experimental process, this section details the hardware and software environment, parameter tuning, and model selection process.
1.1 Hardware and Software Environment
(1) Hardware Environment
- Processor (CPU): Intel i5-12600KF with 12 cores, max frequency 4.9GHz.
- Memory (RAM): 16GB DDR5.
- Graphics Processing Unit (GPU): AMD RX6500XT with 4GB GDDR6.
- Storage (SSD): 980 NVMe PCIe SSD for fast data loading and model parameter access.
(2) Software Environment
- Programming Tools: Visual Studio Code (VS Code) and Jupyter Notebook.
- Frameworks: TensorFlow 2.4 and Keras 2.4.3.
- Data Processing: OpenRefine, NumPy, and Pandas.
- Visualization: Matplotlib and Seaborn.
1.2 Parameter Settings
To build a CNN-LSTM-based sentiment analysis model, hyperparameters are carefully considered:
- Layers: 3 CNN layers and 2 LSTM layers.
- Neurons: 128 neurons per CNN layer and 150 LSTM units.
- Kernel Size: 3x1, 4x1, and 5x1 to capture different text patterns.
1.3 Using Pretrained Word Vectors
BERT pretrained word vectors are used as input to leverage existing language model resources, providing rich semantic understanding and improving training efficiency.
2 Network Architecture Design
A composite neural network architecture combining Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) networks is designed to effectively capture sentiment tendencies in customer reviews.
2.1 CNN Design
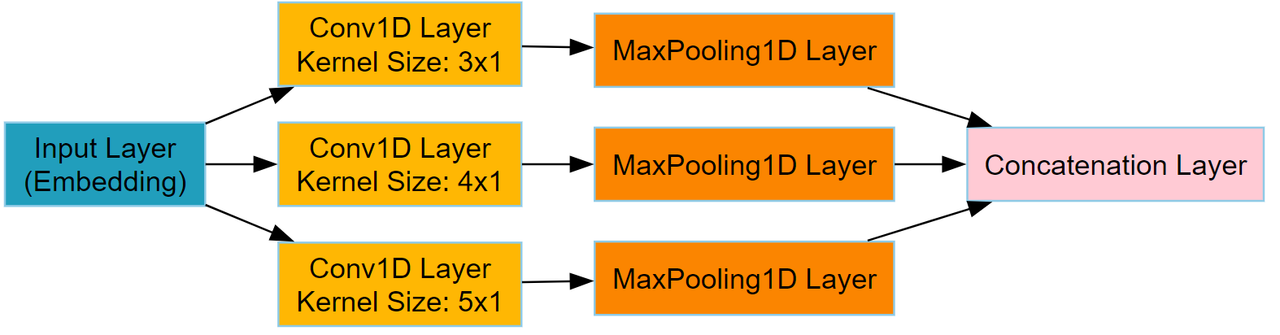
- Convolutional Layers: Three different sizes of convolution kernels (3x1, 4x1, 5x1).
- Pooling Layers: Max pooling layers to reduce feature dimensions and improve generalization.
- Activation Function: ReLU activation function for non-linear features and better gradient propagation.
2.2 LSTM Design

Bidirectional LSTM layers are introduced to capture forward and backward dependencies in text, with 128 units to balance performance and computational cost.
2.3 Fully Connected and Output Layers
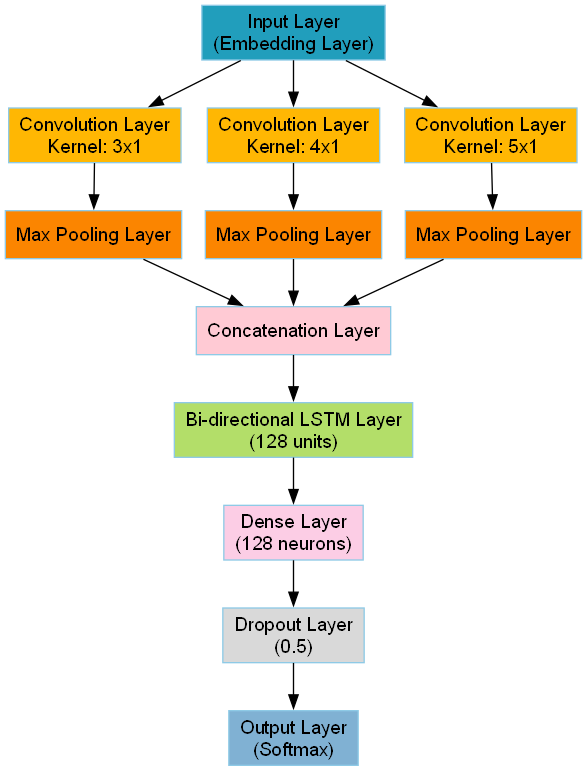
- Fully Connected Layers: Integrate features from CNN and LSTM layers for classification.
- Dropout: Applied to reduce overfitting.
- Output Layer: Softmax activation function to output sentiment probabilities.
3 Model Training
The model training process includes data preprocessing, optimization strategies, and performance monitoring:
- Training Strategy: Adam optimizer, batch size of 8, early stopping to prevent overfitting.
- Overfitting Prevention: Dropout and L2 regularization.
- Performance Monitoring: Callback functions to monitor validation performance and save the best model.
4 Hyperparameter Tuning
Grid search and random search strategies are used to fine-tune hyperparameters:
- Learning Rate: Optimal at 0.005 for balance between convergence speed and stability.
- CNN and LSTM Parameters: Adjusted filter sizes, kernel sizes, and LSTM units for best performance.
- Fully Connected Layers: 128 neurons with dropout rate of 0.5.
5 Model Performance Evaluation
Standard evaluation metrics are used to assess model performance:
- Accuracy: Overall correctness of predictions.
- Recall (Sensitivity): Ability to identify positive samples.
- Precision: Correctness of positive predictions.
- Specificity: Ability to identify negative samples.
- F1 Score: Harmonic mean of precision and recall.
6 Baseline Models
To evaluate the CNN-LSTM model, its performance is compared with several baseline models:
- Single CNN Model: Captures local text features with convolutional layers.
- Single LSTM Model: Captures sequence dependencies with LSTM layers.
- Support Vector Machine (SVM): Classifies data using a hyperplane in a high-dimensional space.
- Naive Bayes: Uses probabilistic models for classification based on Bayes' theorem.
- Random Forest: Uses multiple decision trees for robust classification.